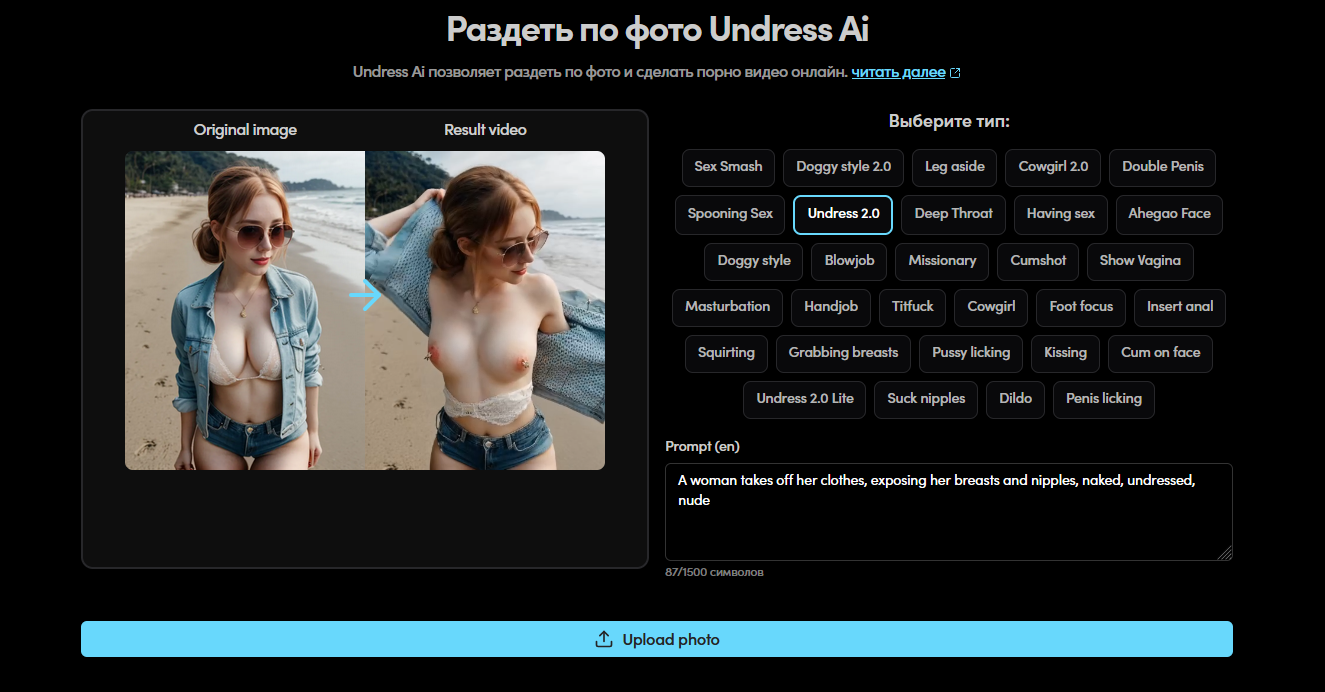
Wie man NSFW-Bilder und Fotos mit einem neuronalen Netzwerk generiert. Erfahren Sie, wie die NSFW-Bildgenerierung mit neuronalen Netzwerken und KI-generierten Porno- Fotos funktioniert. Wir betrachten beliebte Tools zur Erstellung von NSFW-Bildern, Fotos und Videos. Alles ist einfach, schnell und ohne technische Komplikationen.
Wenn schnell realistische NSFW-Bilder ohne komplexe Einstellungen und manuelles Rendering benötigt werden, wird die NSFW-Bildgenerierung mit neuronalen Netzwerken verwendet: Eine Textanfrage wird eingegeben oder eine Referenz hochgeladen, ein Modell wird ausgewählt, Winkel und Beleuchtung werden festgelegt und der Prozess gestartet. Der NSFW-Foto- Generator setzt das Ergebnis basierend auf dem Prompt zusammen, bietet Parameterkontrolle und Export in der gewünschten Auflösung. Dieser Ansatz gewährleistet vorhersehbare Qualität, Reproduzierbarkeit und Zeitersparnis.
Wie man NSFW-Bilder und Fotos mit einem neuronalen Netzwerk erstellt
Um ein vorhersehbares visuelles Ergebnis zu erhalten, reicht es aus, eine klare Reihenfolge der Aktionen einzuhalten: Beschreibung des Bildes im Prompt, Auswahl des Modells und Stils, gezielte Anpassungen über LoRA, dann Seitenverhältnis und Start. Jede Phase des Prozesses baut auf der vorherigen auf: Ein klar definierter Prompt hilft dem Modell die Aufgabe zu interpretieren, der Stil bildet den visuellen Kontext und zusätzliche Parameter verfeinern die Details. Unten ist ein Algorithmus, der zeigt, wie der vollständige Generierungszyklus aufgebaut ist — vom Text zum fertigen Bild.
Schritt 1. Arbeitsbereich
In dieser Phase öffnet sich der Arbeitsbereich, in dem alle Generierungstools konzentriert sind: Modellauswahl, Stil, LoRA und zusätzliche Parameter. Hier findet die Hauptkonfiguration des Prozesses vor dem Start der NSFW-Bildgenerierung statt.
Schritt 2. Prompt-Formulierung
Die Phase, in der die Schlüsselparameter des zukünftigen Bildes festgelegt werden. Das Ziel ist das Bild so zu beschreiben, dass das Modell die Schlüsselmerkmale reproduziert.
Was wichtig ist anzugeben:
Aussehen: Haarfarbe/-länge, Augenmerkmale;
Bildausschnitt und Licht: Winkel, Beleuchtungstyp, Hintergrund;
Details: Accessoire, Geste, Umgebungselement.
Beispiel (neutral):
(masterpiece, best quality), 1girls, 2boy, gentle smile, long wavy chestnut hair, hazel eyes, soft warm lighting, red background, leaves drifting, detailed clothing folds, calm atmosphere, intricate details, shallow depth of field, porn, sex, hentai
Prompt-Analyse
Klammern ( … ) — erhöhen das Gewicht eines Begriffs: (masterpiece), (best quality). Die Verstärkung kann verdoppelt werden: ((masterpiece)) oder explizit: masterpiece:1.5.
Danbooru-Format-Tags: 1girl — ein Charakter im Bild; ähnlich 2girls, 1boy usw.
Andere Tags legen Gesichtsausdruck, Haare, Licht, Hintergrund und Stimmung fest.
Wenn das Schreiben des Prompts selbst schwierig ist, kann die eingebaute Help-Funktion verwendet werden — sie analysiert den eingegebenen Text und ergänzt ihn automatisch mit Beschreibungen von Details, Stil und Stimmung in jeder Sprache. Dieses Tool ermöglicht es, Anfragen korrekt zu verfeinern, einschließlich solcher, die aufgrund von Einschränkungen bei expliziten Szenen nicht über ChatGPT erstellt werden können.

Schritt 3. Modellauswahl
Das Modell bestimmt den visuellen Stil und das Detailniveau des Bildes. Jedes ist auf einem anderen Datensatz trainiert und hat seine eigene "Handschrift": Einige erstellen weiche Aquarellästhetik, andere — realistische Bilder mit hohem Kontrast und präziser Hell-Dunkel-Malerei.

Die falsche Modellauswahl kann die beabsichtigte Idee verzerren, daher ist es in der Vorbereitungs- phase wichtig, mehrere Optionen zu testen.
Beispiel:
Für einen weichen, romantischen Anime-Stil eignet sich Realistic.
Für ein kontrastreicheres und moderneres visuelles Erscheinungsbild — Bento.
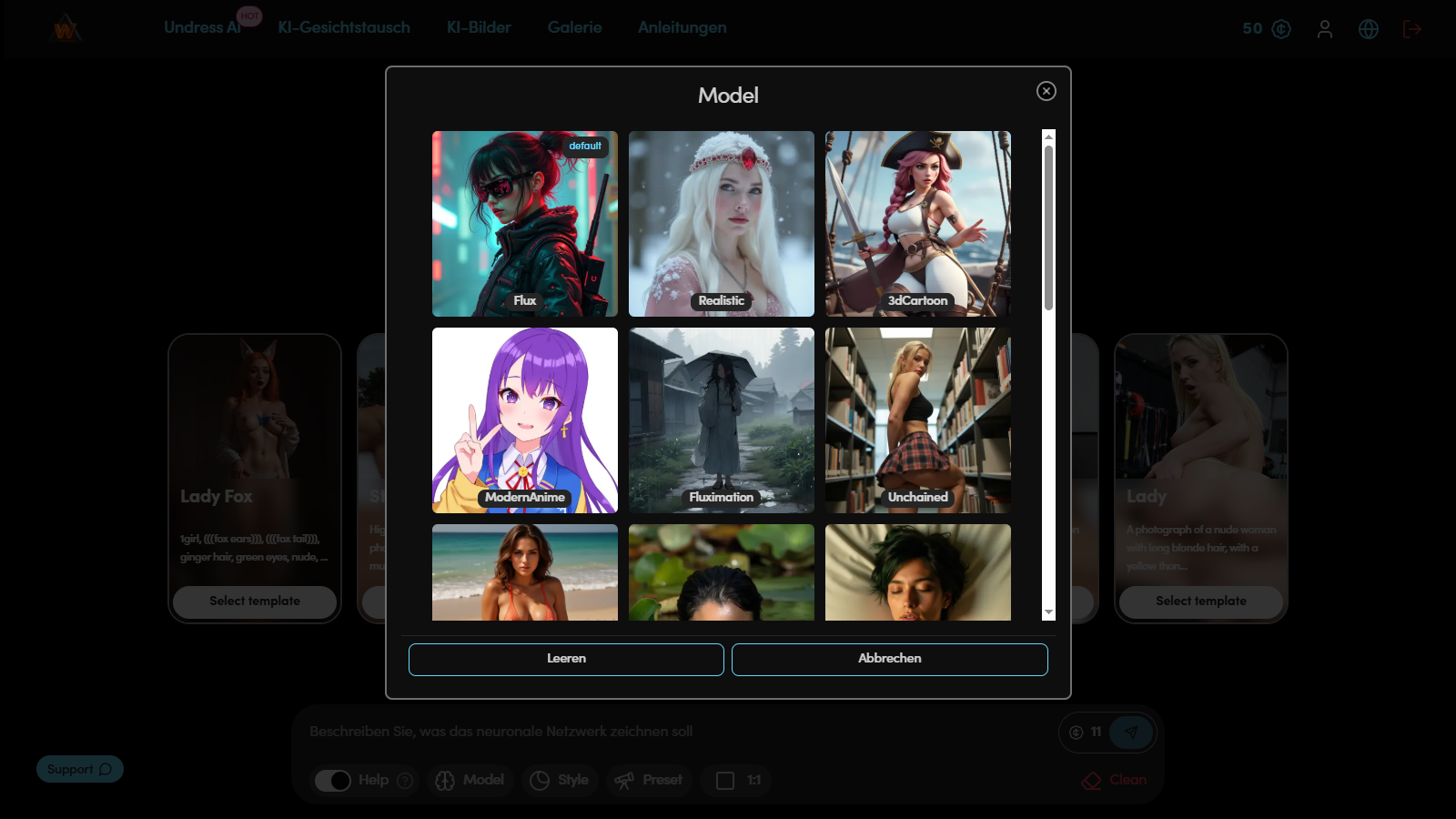
Um die Unterschiede zu bewerten, wird derselbe Prompt verwendet:
A cosmic priestess of impossible grace floats at the core of the Shattered Bloom Nebula, shaping gravity with a mere gesture. Her radiant, ethereal form shimmers with living constellations, each breath sending ripples of starlight through the nebula's fractured petals. Wisps of bioluminescent orchid petals swirl around her, porn, hentai, anime, sexy, erotic.
Es reicht aus, die Generierung mit zwei verschiedenen Modellen zu starten und Textur, Lichtbehandlung und Linienzeichnung zu vergleichen. Dies ermöglicht es zu bestimmen, welches Modell näher am beabsichtigten Ergebnis liegt und die visuelle Atmosphäre der Szene besser vermittelt.
Schritt 4. Stilauswahl
Der Stil legt die visuelle Umgebung und den emotionalen Ton des Bildes fest. Er bestimmt nicht nur den Hintergrund, sondern auch die Art der Beleuchtung, die Farbpalette und die Atmosphäre der Szene. Derselbe Prompt in verschiedenen Stilen kann völlig anders aussehen — von realistischem Fotografieren bis hin zu Anime-Bildern oder malerischen Illustrationen.

Zweck des Stils:
Klärt den Kontext (Porträt, Innenraum, Landschaft, futuristische Szene);
Steuert die Wahrnehmung von Emotionen und Licht;
Hilft, eine Reihe von Bildern zu vereinheitlichen.
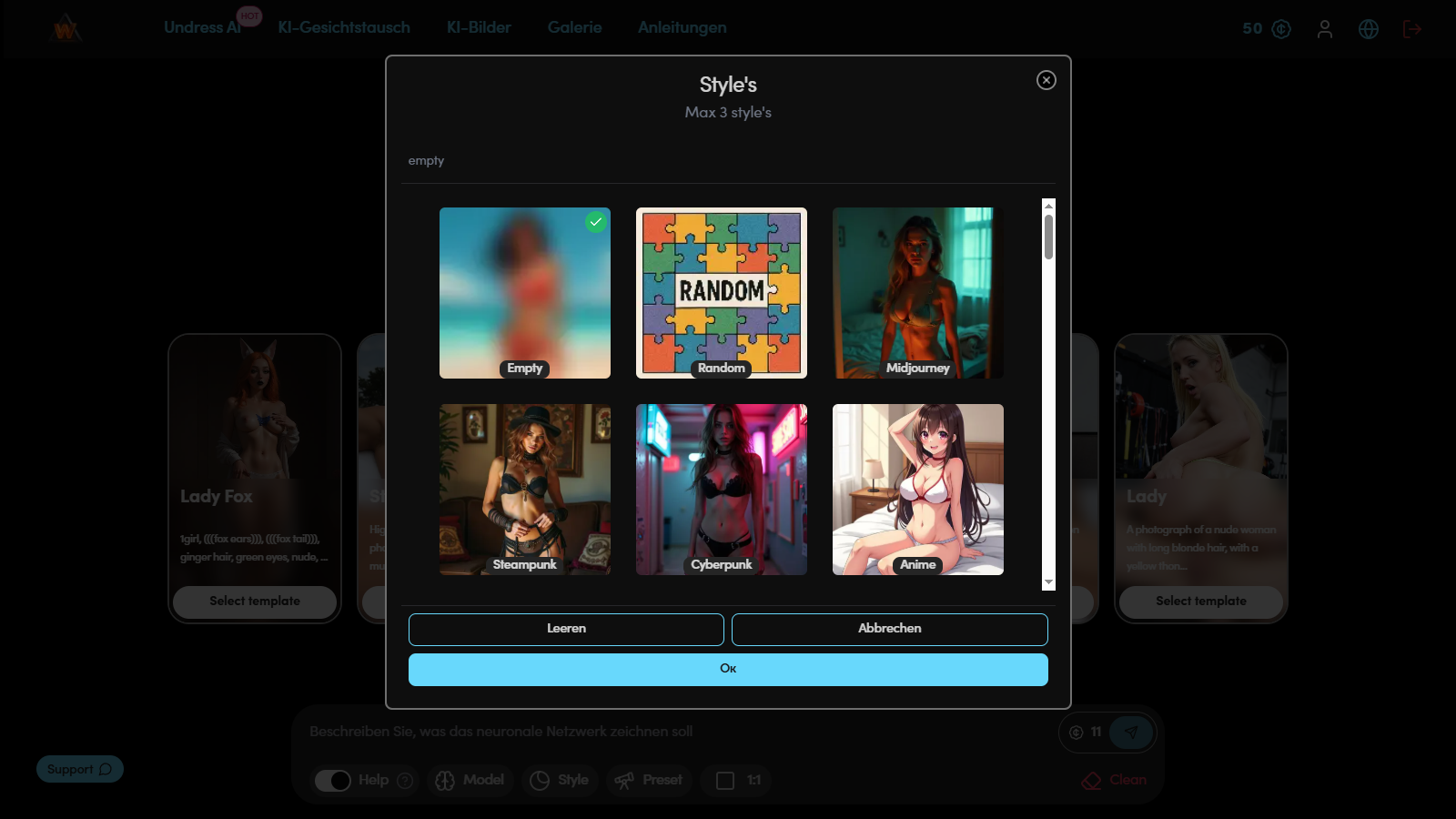
Beispiel-Prompt zum Testen:
(masterpiece, best quality, 1girl, solo, gentle smile, long wavy pink hair in a high ponytail, heterochromia (hazel and blue eyes), round glasses, mecha pilot suit, detailed clothing folds, soft warm lighting, autumn park background, depth of field:1.1)
Beim Wechseln der Stile, zum Beispiel von Impressionist Painting zu Studio Photography oder Anime Cinematic, ändern sich die Akzente: Im ersten Fall sieht das Bild weicher und texturierter aus, im zweiten — schärfer, mit klarem Licht und realistischeren Schatten. Das Testen eines Prompts in mehreren Stilen hilft, das optimale visuelle Format für die weitere Generierung zu finden.
Schritt 5. Anwendung von Preset (LoRA)
LoRA wird zur Feinabstimmung der visuellen Eigenschaften des Bildes verwendet. Wenn das Modell die allgemeine Struktur festlegt, steuert LoRA die Details — Gesichtstyp, Zeichenstil, Kleidungselemente oder Schattierungs- charakter.

Zweck von LoRA:
Verbesserung der Gesichtszüge und Proportionen;
Änderung der Stilistik (Anime, Realismus, Comic usw.);
Hervorhebung einzelner Szenelemente (Stoff, Beleuchtung, Pose).
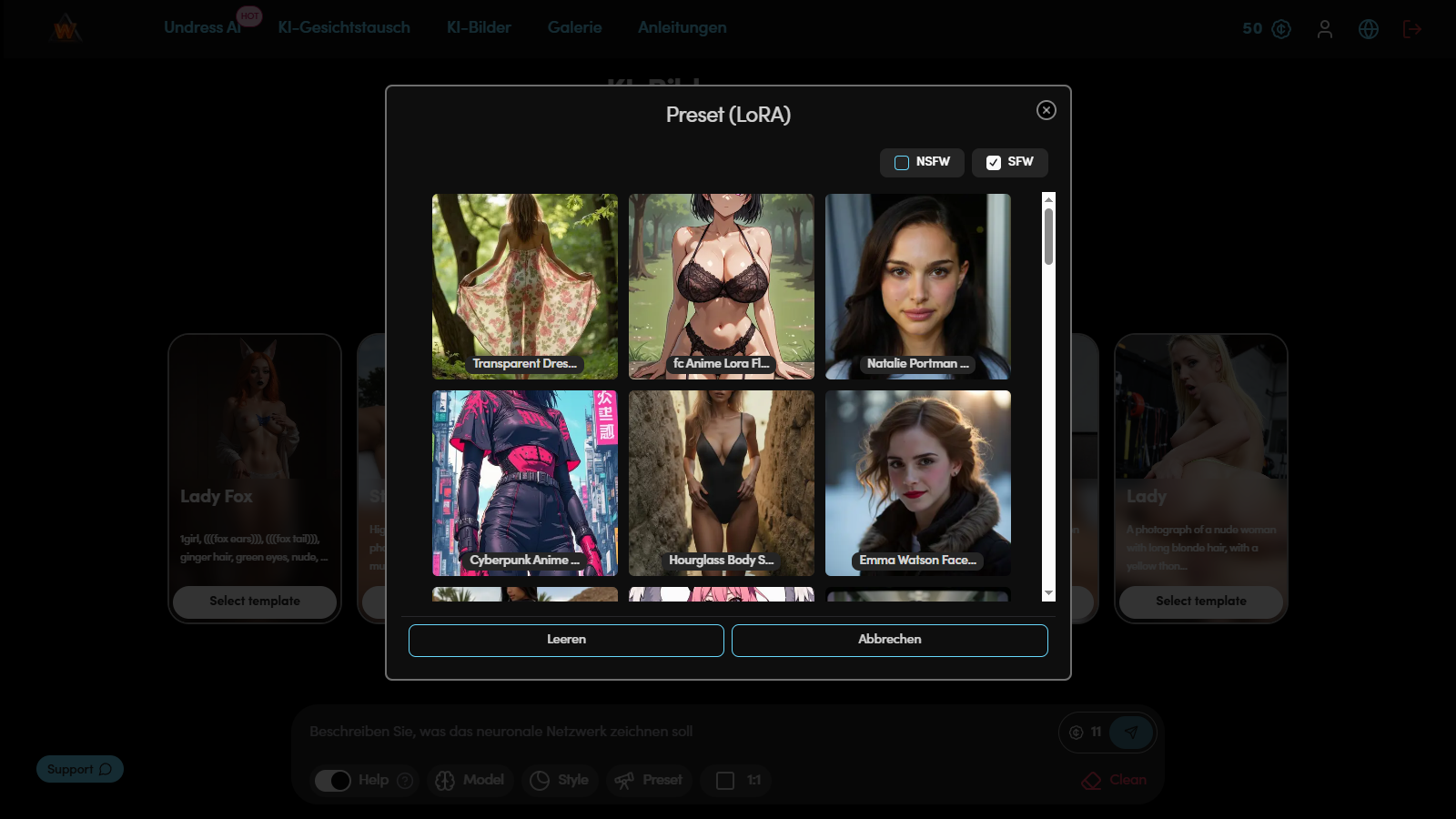
Beispiel-Prompt:
(masterpiece, best quality, 1girl, solo, gentle smile, long wavy blond hair in a high ponytail, heterochromia (hazel and blue eyes), round glasses, mecha pilot suit, sheer fabric accents, detailed clothing folds, soft warm lighting, red background, depth of field:1.1)
LoRA: Dissolve Style
Um den Einfluss von LoRA zu bewerten, wird das Bild zweimal generiert — ohne und mit ihm. Der Vergleich hilft zu bestimmen, wie stark sich Gesichtsausdruck, Textur oder Beleuchtung, andere Bilddetails verändert haben. Bei korrekter Einstellung fügt LoRA Ausdruckskraft hinzu und verbessert die visuelle Qualität ohne Verzerrung der ursprünglichen Komposition.
Schritt 6. Seitenverhältnis
Das Seitenverhältnis bestimmt die Bildkomposition und beeinflusst die Wahrnehmung der Szene. Dieser Parameter legt das Bildformat fest und hilft, die Aufmerksamkeit auf die gewünschten Details zu lenken.

Hauptoptionen:
9:16 — Porträtformat, Fokus auf Charakter und oberem Teil des Bildes.
16:9 — breiter, kinematografischer Winkel, ermöglicht die Darstellung der Umgebung.
1:1 — ausgewogenes quadratisches Format, praktisch für Vorschauen und Veröffentlichungen.
Die Änderung des Seitenverhältnisses bei gleichem Prompt ergibt unterschiedliche Ergebnisse: Komposition, Proportionen und Bildstimmung ändern sich merklich. Das optimale Format wird für die Aufgabe ausgewählt — Porträt, Szene, Hintergrund oder animierter Bild.
Schritt 7. Verwendung von Vorlagen
Vorlagen vereinfachen den Generierungsprozess, wenn Geschwindigkeit und Stabilität der Ergebnisse wichtig sind. Dies sind fertige Presets, in denen Modell, Stil und LoRA bereits konfiguriert sind.

Der Benutzer wählt eine Vorlage aus, die dem gewünschten visuellen Ergebnis am nächsten kommt, und ändert nur Details — Haarfarbe, Beleuchtung, Gesichtsausdruck oder Hintergrund. Dieser Ansatz reduziert die Zeit für die Vorbereitung des Prompts und gewährleistet vorhersehbare Qualität des endgültigen Bildes.
Checkliste für stabile Ergebnisse bei der Generierung von NSFW-Inhalten
Prompt enthält Aussehen, Licht, Hintergrund, Emotion, Details
Gewicht der Schlüsseltags ist mit Klammern hervorgehoben.
Modell auf einem Prompt gegen eine Alternative getestet.
Stil für die Aufgabe ausgewählt, widerspricht nicht dem Modell.
LoRA stehen nicht in Konflikt und haben moderates Gewicht.
Seitenverhältnis entspricht dem Zweck (Porträt/Vorschau/Bild für Clip).
Typische Fehler bei der Generierung von NSFW-Bildern und Fotos
Überladung mit Qualitäts-Tags: (masterpiece, best quality) reicht aus.
Vermischung inkompatibler Stile: einen führenden Stil beibehalten.
Zu allgemeiner Prompt: 3–4 Konkretisierungen hinzufügen (Haare, Augen, Licht, Hintergrund).
Übermäßige Anzahl von LoRA: nicht mehr als 1–2 gleichzeitig.
Zufälliges AR: entsprechend dem Ziel im Voraus wählen.
Nach dem Start der NSFW-Bild- und Fotogenerierung mit einem neuronalen Netzwerk verarbeitet das System nacheinander alle festgelegten Parameter, und das Ergebnis erscheint auf dem Bildschirm. In dieser Phase verbinden sich Prompt, Modell, Stil und zusätzliche Einstellungen zu einem einzigen visuellen Bild, das dem ursprünglichen Konzept entspricht.
Warum das funktioniert
Das neuronale Netzwerk erstellt Bilder nicht zufällig. Es analysiert die eingegebenen Parameter — Beleuchtung, Winkel, Stimmung und Szenendetails — und bildet das Ergebnis entsprechend der Anfrage. Die Bildqualität hängt direkt von der Genauigkeit der Beschreibung und der Konsistenz der ausgewählten Tools ab.
Durch das Beherrschen des vollständigen Prozesses der Generierung von NSFW-Bildern und Fotos mit neuronalen Netzwerken können Sie schnell stabile Ergebnisse erstellen, verschiedene Varianten eines Charakters bilden oder völlig neue visuelle Bilder mit vorhersehbarem Stil und Detailniveau entwickeln.